
With xAI’s Grok 4 receiving much engagement lately, many are sleeping on the new open-source and high-performance coding model, Kimi K2. Developed by Moonshot AI, Kimi K2 is a language model with 32 billion activated parameters and 1 trillion total parameters. It is open-source, so the budget shouldn’t be a problem. And it performs, so there’s that as well. Based on that, does it make sense for developers to replace Claude 4 or Grok 4 with the Kimi 2? Let’s find out.
After extensive testing and benchmark analysis, we’ve put these three AI powerhouses head-to-head to help you choose the right coding companion for your needs.
Kimi K2: The Open-Source Challenger to Claude 4
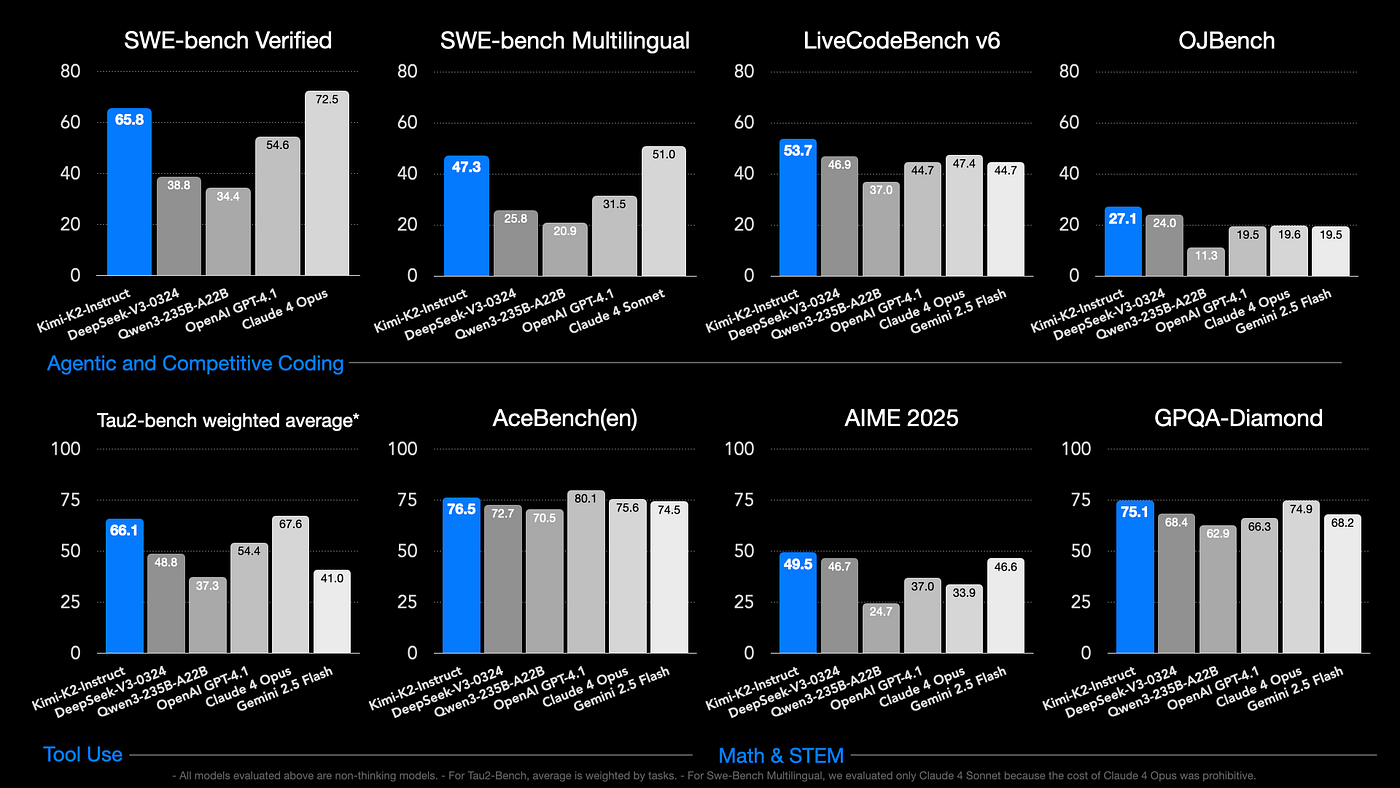
Kimi K2 represents a significant leap forward in open-source AI models. Built by Moonshot AI with backing from Alibaba, this massive model packs 1 trillion parameters with 32 billion activated through its Mixture-of-Experts (MoE) architecture. What sets Kimi K2 apart is its agentic intelligence – the ability to execute tasks and make decisions without constant human guidance autonomously.
The model offers an impressive 128K token context window, allowing it to process entire codebases in a single session. This makes it particularly valuable for developers working on large, complex projects where understanding the full context is crucial.
Claude 4 (Sonnet/Opus): The Current Benchmark
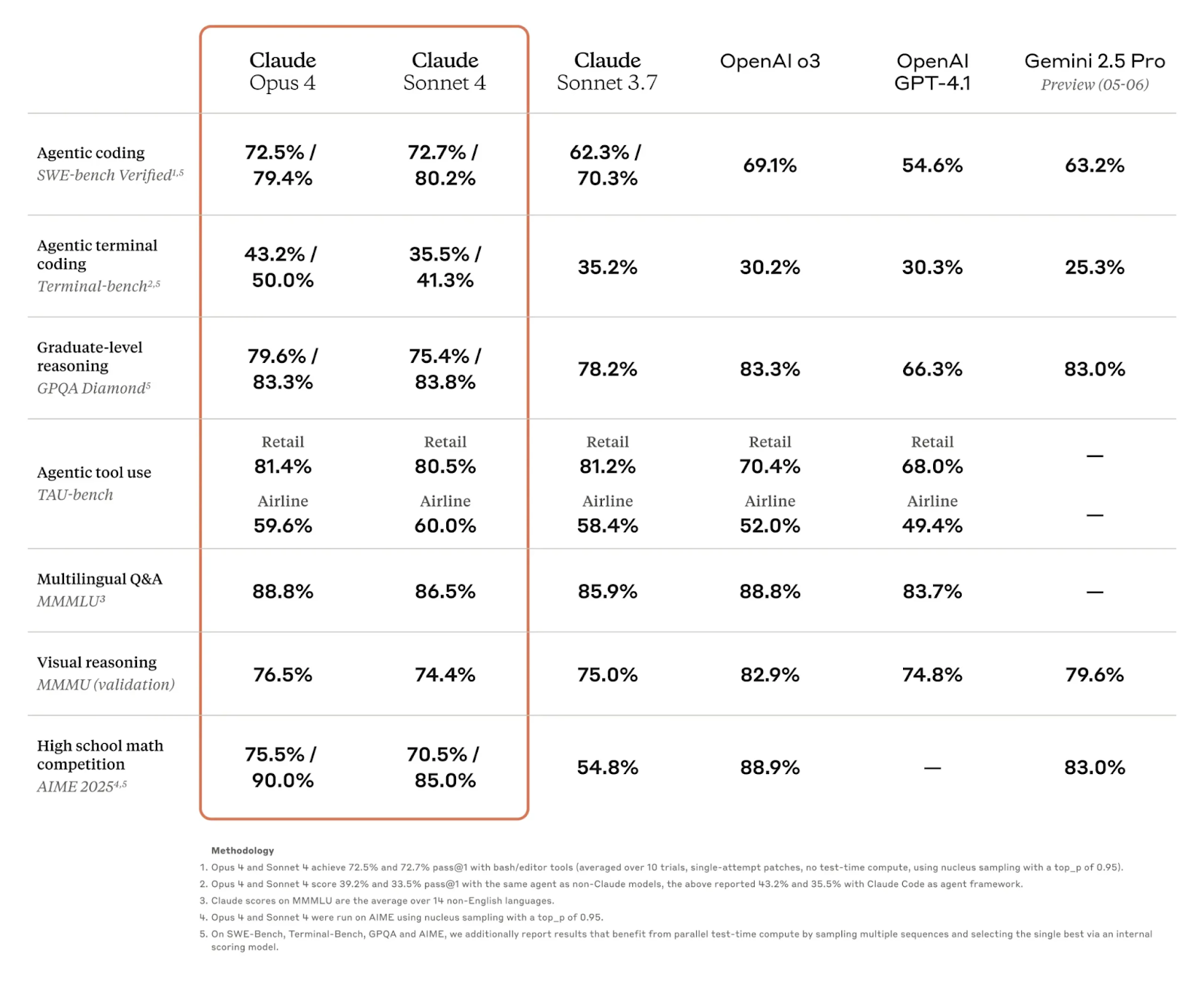
Anthropic’s Claude 4 lineup includes two main variants, as we’ve discussed before: Claude Opus 4 and Claude Sonnet 4. These models represent what Anthropic calls “the world’s best coding model”, with Opus 4 designed for complex, long-running tasks and Sonnet 4 offering a balance between power and efficiency.
The standout feature of Claude 4 is its ability to maintain autonomous coding sessions lasting up to seven hours. This represents a fundamental shift from quick-response tools to sustained collaboration partners that can work through complex programming challenges without constant supervision.
Grok 4: xAI’s Reasoning Powerhouse
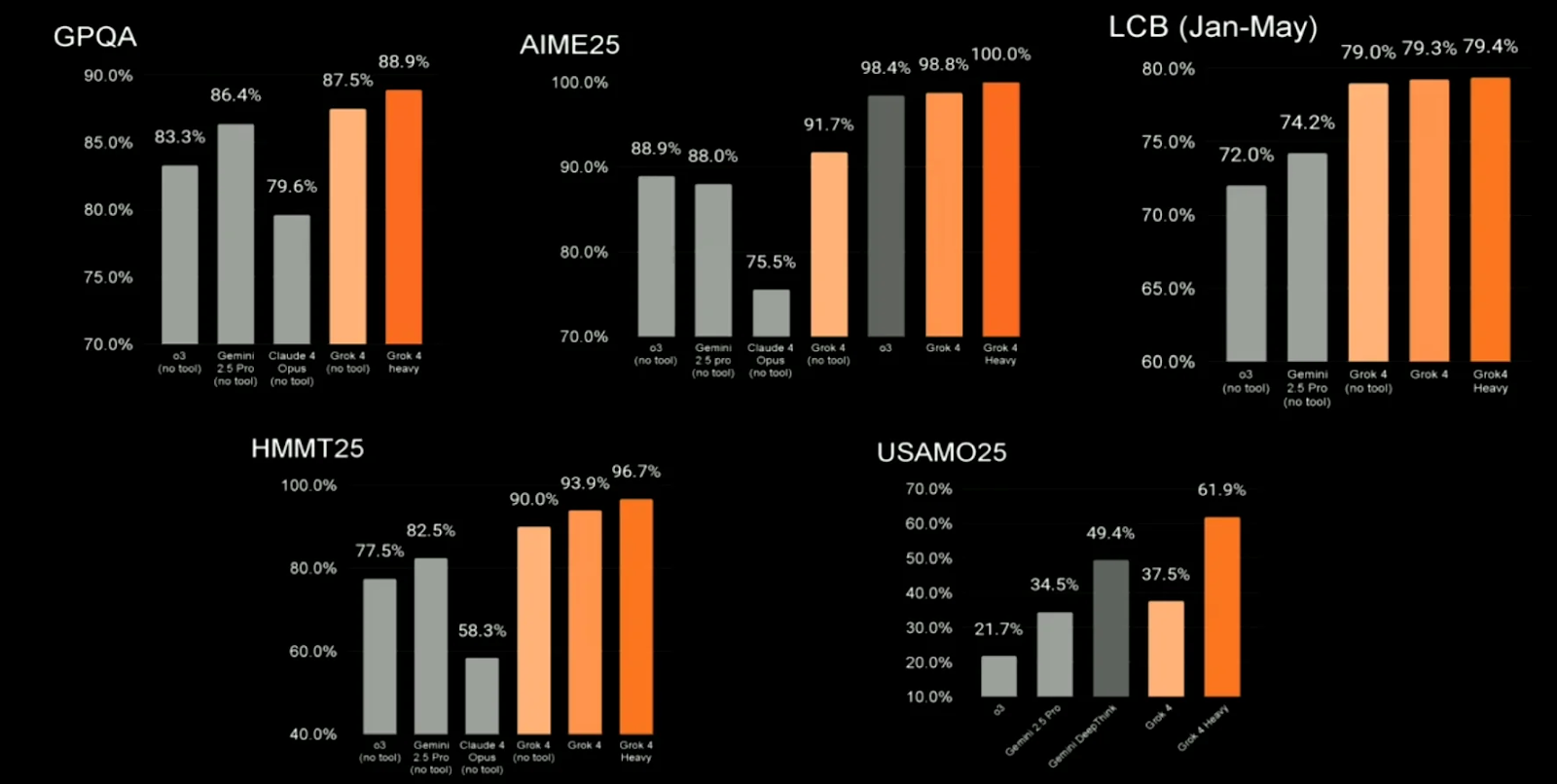
xAI’s Grok 4 takes a different approach, focusing heavily on advanced reasoning capabilities. Available in two tiers – standard Grok 4 and the premium Grok 4 Heavy – this model uses xAI’s Colossus supercomputer with 200,000 GPUs for training.
Grok 4’s unique selling point is its real-time data integration through X (formerly Twitter), providing up-to-date information and context that other models lack. The model also features a 256,000-token context window, making it suitable for processing extensive documentation and codebases.
Kimi K2 vs Claude 4 vs Grok 4: Benchmark Comparison
SWE-bench
The SWE-bench benchmark tests AI models’ ability to solve real-world software engineering problems by having them generate patches for GitHub issues. Here’s how our three contenders stack up:
Claude 4 Performance:
- Claude Sonnet 4: 72.7% on SWE-bench Verified
- Claude Opus 4: 72.5% on SWE-bench Verified
Kimi K2 Performance:
- 65.8% on SWE-bench Verified (single attempt)
- 71.6% with parallel test-time compute
Grok 4 Performance:
- Standard Grok 4: ~72-75% on SWE-bench (reported)
- Ranks #2 in coding on LMArena benchmarks
Claude 4 takes the lead in this crucial benchmark, with both Sonnet and Opus variants outperforming the competition. However, Kimi K2’s performance is remarkable for an open-source model, coming surprisingly close to the proprietary leaders.
LiveCodeBench
LiveCodeBench tests models on practical coding tasks with real code execution requirements:
- Kimi K2: 53.7% accuracy
- Claude Sonnet 4: 48.5% accuracy
- Claude Opus 4: 47.4% accuracy
- Grok 4: 79.4% (reported best performance)
Here, Grok 4 shows impressive results, though some reports suggest these numbers may not reflect the typical user experience due to computational resource differences.
Kimi K2 vs Claude 4 vs Grok 4: Code Quality and Consistency

Kimi K2 excels at tool calling and execution, making it particularly strong for agentic coding scenarios where the AI needs to interact with external systems and APIs. Its strength lies in executing well-defined plans rather than initial strategy formulation. The Reddit screenshot above suggests Kimi K2 can effectively handle big, complicated tasks.
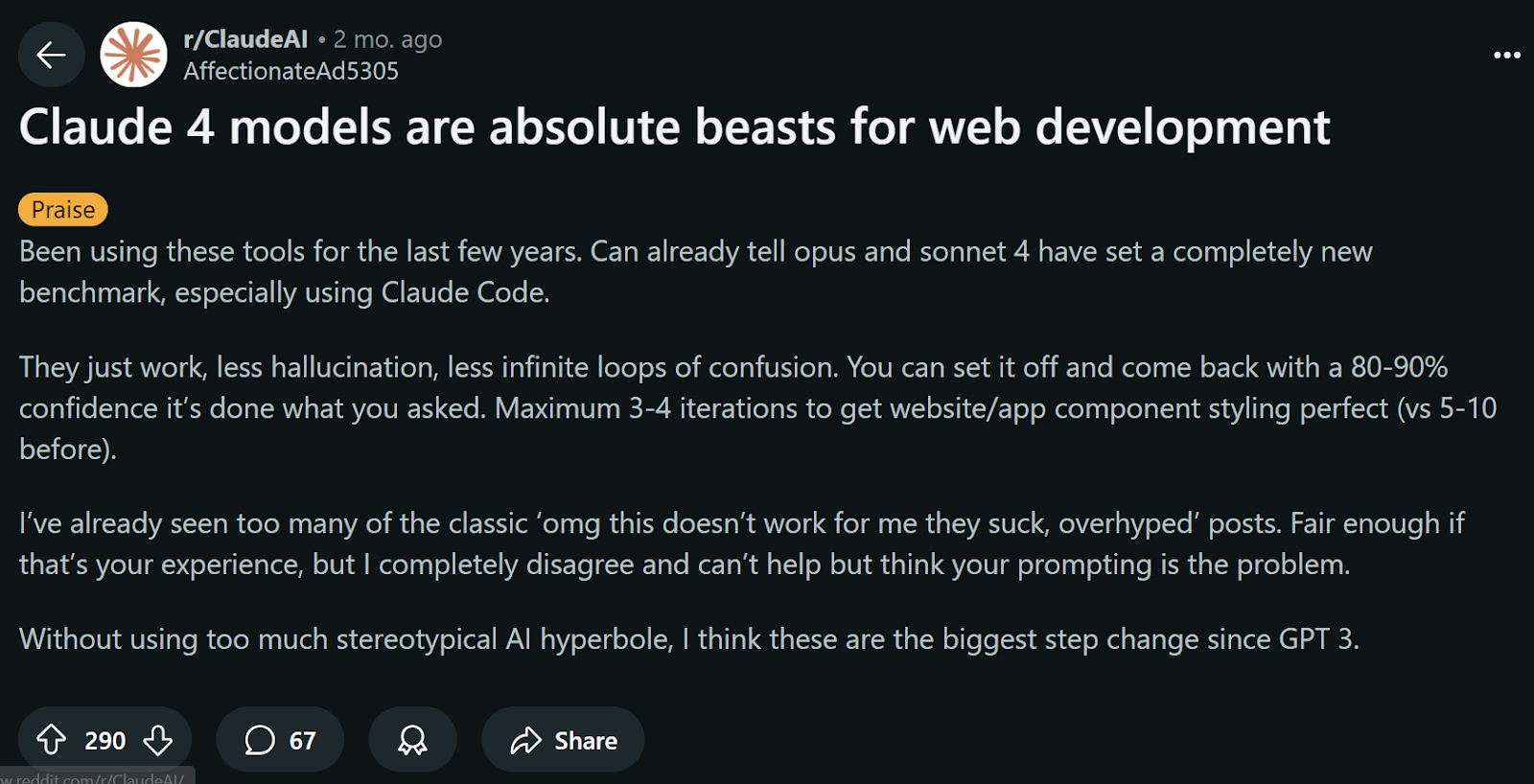
Claude 4 consistently produces cleaner, more maintainable code, and such was the experience of the Reddit user u/AffectionateAd5305. Developers report that it follows software engineering best practices and avoids shortcuts that could introduce technical debt. The model’s “reduced reward hacking” means it chooses proper solutions over quick fixes.
Grok 4 demonstrates superior debugging capabilities, with developers noting its ability to spot complex bugs that other models miss. However, it can be bursty when handling exceptionally long reasoning chains, occasionally losing track of earlier context. Despite this, its deep inferencing often uncovers subtle logic errors that other models miss. The X post above by @Techartist shows the high quality of the outputs Grok 4 is capable of.
Kimi K2 vs Claude 4 vs Grok 4: Integration and Extensibility
API & Tooling Support
Kimi K2
Moonshot AI provides a fully documented REST API and SDKs for Python, JavaScript, and Java. Out-of-the-box support includes direct access to a sandboxed execution environment, enabling live tool calls, database queries, and CI/CD pipeline triggers.
Claude 4
Anthropic offers both API and first-party IDE plugins for VS Code and JetBrains. The CLI tool “claude-cli” allows batch processing of codebases, while Anthropic’s “Anthropic Agent” framework simplifies building custom developer assistants.
Grok 4
xAI’s Grok integrates tightly with X’s data stream via real-time webhooks, plus open SDKs for Python and Ruby. Its native “Project Brain” feature ingests Git repositories and documentation automatically, producing adaptive code suggestions keyed to active branches.
Ecosystem & Community
Kimi K2
As an open-source project under the Apache 2.0 license, Kimi K2 benefits from a rapidly growing community. Dozens of community-built plugins mitigate vendor lock-in and add language-specific linters, test generators, and security analyzers.
Claude 4
Anthropic’s commercial focus means extensions are primarily developed in-house or by vetted partners. The Claude Developer Forum, however, hosts regular hackathons and a bounty program for community-submitted prompt libraries.
Grok 4
xAI maintains a curated ecosystem: partners can build certified Grok “skills” for domain-specific workflows (e.g., fintech, bioinformatics). While less open than Kimi, this model ensures stability and security in regulated environments.
Kimi K2 vs Claude 4 vs Grok 4: Pricing and Licensing
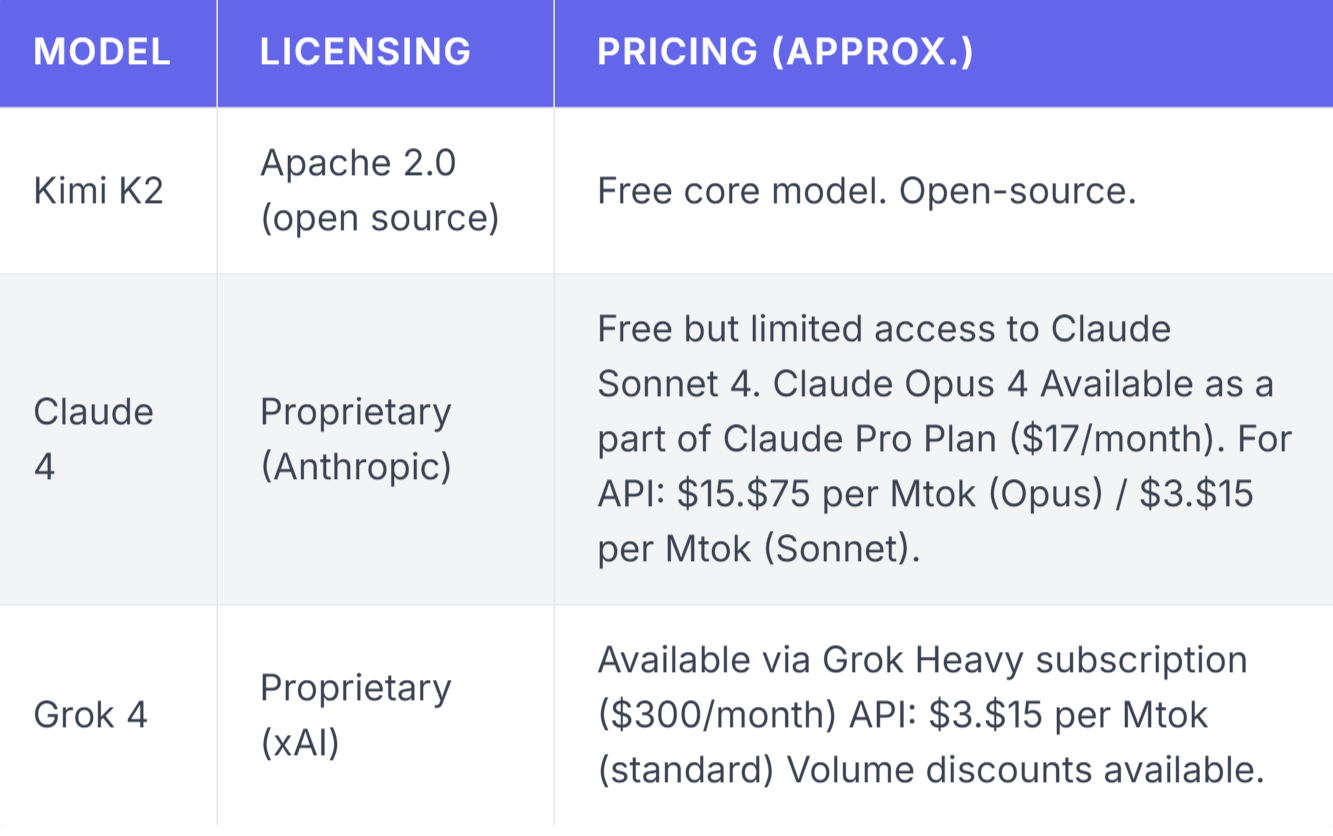
While Kimi K2 wins on cost for open-source enthusiasts, Claude 4 and Grok 4 offer enterprise SLA guarantees and dedicated support channels.
Kimi K2 vs Claude 4 vs Grok 4: Use-Case Deep Dive
Large-Scale Legacy Codebases
- Kimi K2’s 128K context window handles monolithic systems best, reconstructing cross-module call graphs and suggesting end-to-end refactors.
- Claude 4 can maintain long autonomous sessions, ideal for multi-hour code review sprints, but its 64K window may truncate extremely large repositories.
- Grok 4’s 256K window excels at entire-repo analysis, and real-time data fetch means it can pull in external SDK docs on the fly.
Rapid Prototyping & Exploratory Coding
- Claude Sonnet 4 sped up prototyping by generating scaffold projects, including tests and CI configs, in under a minute.
- Grok 4 Heavy offered the richest boilerplate generation, often initializing full microservice architectures with Docker, Kubernetes manifests, and sample payloads.
- Kimi K2 proved most flexible to user-authored prompt flows, seamlessly integrating with custom testing harnesses.
Debugging & Maintenance
- Grok 4 stands out in pinpointing elusive bugs, especially in multithreaded or async code.
- Claude 4 documents and rationalizes each fix, making it easier to onboard new team members.
- Kimi K2 shines in automated regression test generation, catching edge-case failures before deployment.
Kimi K2 vs Claude 4 vs Grok 4: Strengths and Trade-Offs
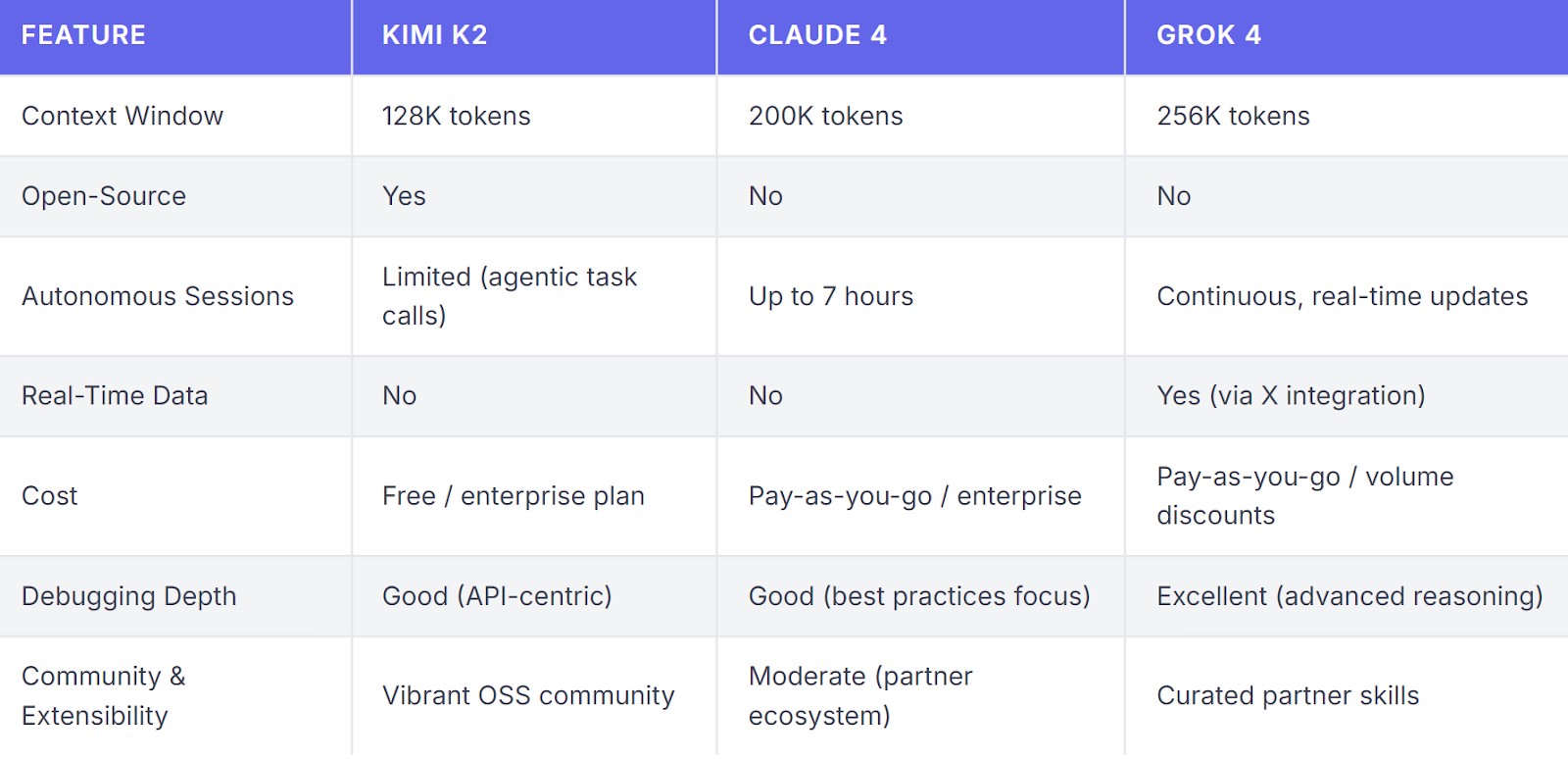
Here’s a feature comparison between Kimi K2 vs Claude 4 vs Grok 4:
The Bottom Line
Choosing the best coding AI comes down to your priorities. If cost efficiency and deep customization are key, Kimi K2 stands out. For professional development workflows that demand high code quality and can run for long, unattended stretches, Claude 4 offers enterprise-grade reliability. Meanwhile, Grok 4 leads the pack when it comes to cutting-edge debugging, real-time data handling, and tackling projects that require massive context windows.
Each of these models pushes the limits of what AI can do for developers. That said, if you’re looking for a place where you don’t have to stick to one model or one ‘way,’ consider Bind AI, which offers you access to Claude 4, Gemini 2.5 Pro, OpenAI o3, DeepSeek R1, and more + a full, cloud IDE for your coding workflows. Try Bind AI now!