
The open-source theatre of reasoning and coding models is growing and continues to impress. In this article, we’ll compare Mistral AI’s Magistral and Devstral with DeepSeek R1. All three models deliver, but not equally. Let’s find out how and why.
What is Magistral?

Mistral AI’s Magistral, introduced on June 10, 2025, is the company’s first specialized reasoning model. It comes in two variants: Magistral Small, a 24-billion-parameter open-source model, and Magistral Medium, an enterprise model available via Mistral’s API. Built on Mistral’s Small/Medium 3 base models, Magistral uses reinforcement learning for step-by-step reasoning, making it efficient at tasks that require deep thinking. It also supports various languages and exhibits some multimodal capabilities.
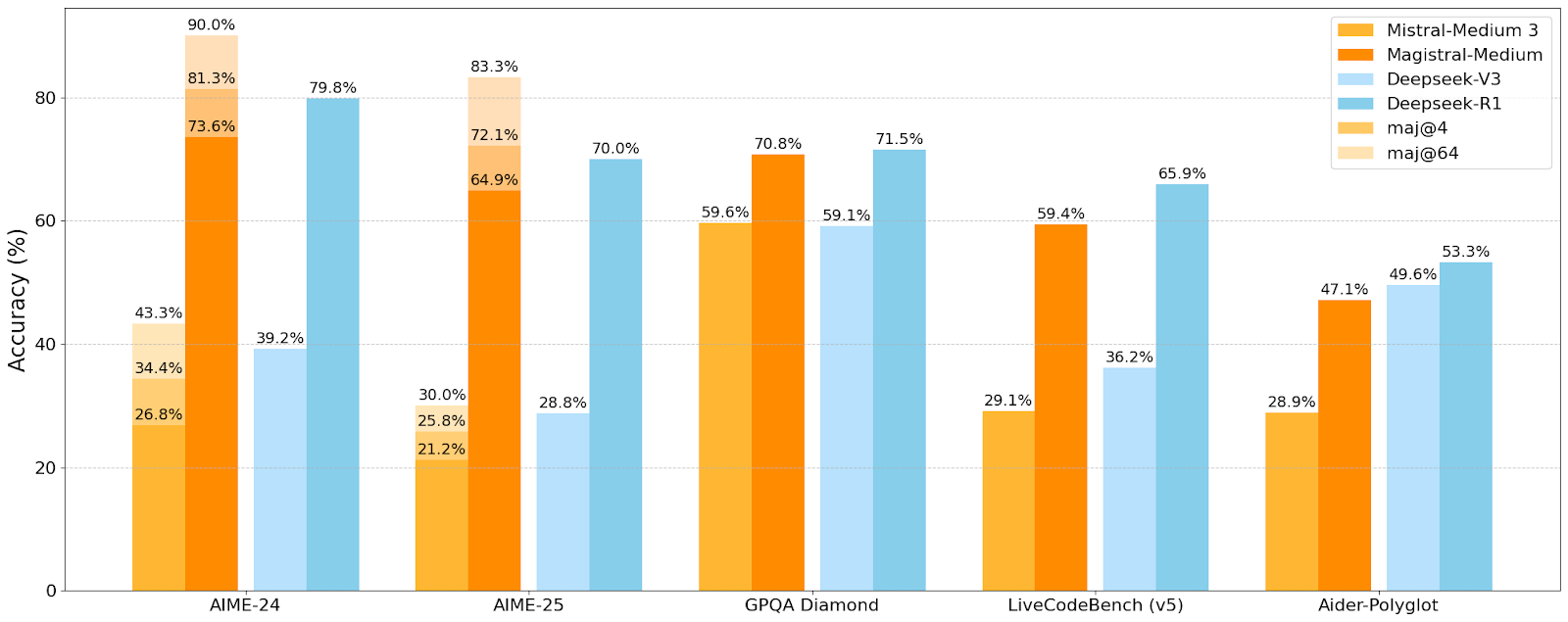
Magistral Small can run locally on a single high-end NVIDIA GPU (ref: RTX 4090/5090) or a 32 GB MacBook. On the other hand, Magistral Medium is accessible through Mistral’s La Plateforme API and major cloud services. In benchmarks, Magistral Medium scored 73.6% on the AIME-24 math-reasoning test, with enhancement through majority voting. Notably, its “Flash Answers” mode offers up to 10× faster token throughput, positioning Magistral as a significant player in advanced reasoning models.
Magistral vs Devstral vs DeepSeek R1: Comparative Performance Benchmarks
Coding and Reasoning Accuracy
In code-generation benchmarks, three models stand out. DeepSeek R1, a 671B-parameter open model from DeepSeek AI, excels with state-of-the-art scores: 73.2% pass@1 on HumanEval and 69.8% on MBPP, and achieves ~49.2% on SWE Verified tasks in DevOps tests.
Conversely, Mistral’s Devstral, a 24B-parameter model, is tailored for real-world coding challenges, outperforming all open models with a score of 53.6% on the SWE-Bench Verified set and 61.6% for its larger version. Its focus is on agentic scenarios, not traditional benchmarks.
Magistral, while not a dedicated code model, performs well due to reasoning training, scoring 59.4% on LiveCodeBench v5, slightly behind DeepSeek and Codestral on pure coding tasks.
Overall, coding accuracy ranking is: DeepSeek R1 > Devstral (small/medium) > Magistral, with the latter prioritizing broader reasoning capabilities.
Speed and Runtime Performance
Inference speed varies greatly by model size and deployment. Mistral touts that Magistral Medium – especially in its specialized “Flash Answers” mode – achieves 10x the token throughput of typical LLM APIs. In practice, this means Magistral can respond much faster in Mistral’s Le Chat interface, though exact tokens/sec are not publicly reported. Magistral Small, by contrast, runs on a single GPU (RTX 4090) with quantization, so its speed is similar to other 24B models: one can expect a few tokens/ms depending on hardware and precision.
Devstral Small (24B) is similarly lightweight. Mistral notes it “runs on a single RTX 4090 or a Mac with 32GB RAM.” This implies moderate performance on modern GPUs. In open-source setups (e.g., using vLLM or llama.cpp), users report throughput on the order of 5–10 tokens/ms (i.e., 5–10x faster than typical 70B models on the same hardware). Devstral Medium is larger and only available via Mistral’s cloud API; Mistral claims it offers very strong cost/performance vs. big closed models, but exact speed numbers aren’t public.
By contrast, DeepSeek-R1 (671B) is extremely large. It cannot run on a single GPU – even with mixture-of-experts tricks, it needs multi-node setups. However, NVIDIA recently demonstrated very high throughput: using 8 of their new Blackwell GPUs (DGX B200 cluster), they achieved about 253 tokens/second per user on the full DeepSeek-R1 model. (In aggregate, that’s ~30,000 tokens/s with 8-way batching.) Even mid-range GPUs (H100 or H200) at lower precision can reach 100+ tokens/s/user on R1. Of course, on a single consumer GPU R1 would be unusable without model-parallel tools. For practical use, DeepSeek provides smaller distilled versions (e.g., 32B and 70B) that match GPT-4o-mini performance. Those distills can be served more conventionally (e.g., 70B on 2–4 GPUs, 32B on a single 4090), trading some accuracy for speed.
Context Window and Efficiency
All three models have large context windows, with Magistral Small and Devstral Small supporting up to 128K tokens, although performance may degrade beyond ~40K tokens. DeepSeek R1 also offers a 128K context window for its 671B model, reflecting modern trends in long-input LLMs.
In terms of efficiency, Magistral Small and Devstral Small each have ~24B parameters (48B weights), quantizing to about 7–8 GB in FP16 or ~4 GB in INT8, allowing for local deployment on a 24–48 GB card. In contrast, DeepSeek-R1’s 671B model requires clusters of expensive GPUs, though it offers fully open MIT licensing for model outputs, enabling fine-tuning and distillation. Most developers would likely use the distilled 32B or 70B versions, with the latter running on ~2–4 top-end GPUs.
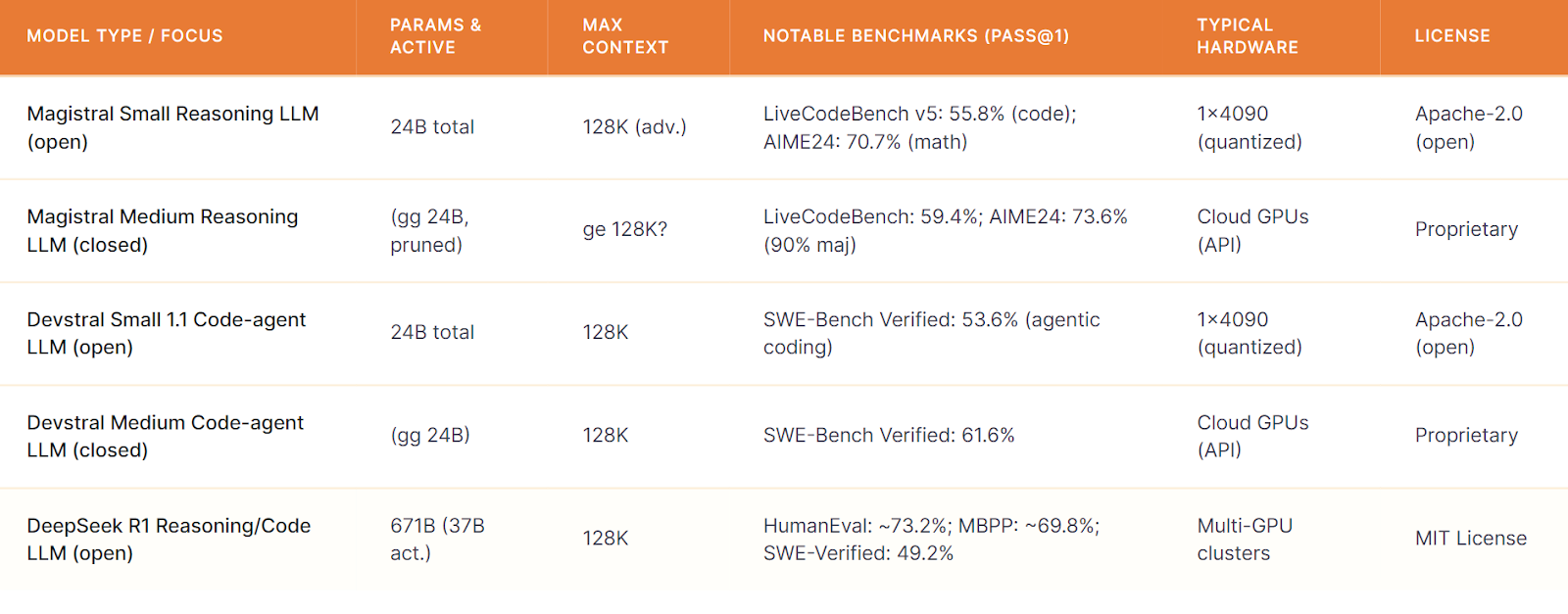
Here’s a detailed technical comparison between the three:
Magistral vs Devstral vs DeepSeek R1: Usability and Integration
Done with the technical side of things, let’s now look at how their usability and integration compare:
Ease of Use and Developer Interface
Magistral Small is open-source and can be downloaded from HuggingFace, running locally with libraries like vLLM or llama.cpp. Mistral provides example prompts, a reasoning system, Le Chat (a web UI), and the La Plateforme API for querying Magistral Medium in a ChatGPT-like manner. It’s also integrated into managed services like SageMaker for enterprise use.
Devstral is similarly accessible, with the 24B “Devstral Small” available for download on platforms like HuggingFace and Kaggle. Mistral recommends using it with code-agent scaffolds like OpenHands, with documentation available. Its API operates at standard Mistral token rates, and Devstral Medium can be accessed via Mistral’s Code API and LangChain/agent frameworks. It works out-of-the-box with VSCode and JetBrains plugins.
DeepSeek-R1 is fully open-source under an MIT license, offering an OpenAI-compatible API (the “deepseek-reasoner” model) and a chat web interface (“DeepThink”). Model weights are available on HuggingFace, allowing integration with frameworks like vLLM or LangChain, along with documented usage patterns.
Documentation and Community Support
Mistral offers official documentation for Magistral and Devstral on their website, including links to an arXiv paper for Magistral and detailed blog posts for Devstral. The HuggingFace model cards for both models feature key details and usage instructions. Additionally, All Hands AI provides tutorials and collaborates on documentation.
DeepSeek maintains a developer site with usage guides and a release page that covers licensing and performance. Their GitHub has the full code and an arXiv citation, while users engage in community discussions on Discord and Reddit. All three models benefit from community support alongside official documentation for troubleshooting.
Integration and Workflows
All three models are designed for modern AI workflows. Magistral and Devstral are HuggingFace-hosted, compatible with HuggingFace pipelines and the transformers/diffusers ecosystem. Mistral provides quantized GGUF versions with integrations in tools like llama.cpp. Magistral supports function-calling and has a documented multi-step reasoning prompt, while Devstral is optimized for code-agent contexts, working with the OpenHands framework and SWE-Agent plugins, including a Docker pull command.
DeepSeek-R1 fits standard pipelines with full R1 (and distill) weights compatible with libraries like vLLM or FastChat. Its OpenAI-compatible API allows for easy migration from ChatGPT/Claude systems, and all code is open-sourced for on-premises use or custom apps. Essentially, these models don’t require proprietary runtimes and integrate with common AI toolkits (LangChain, LlamaIndex, etc.) along with reference code.
Try these Coding & Reasoning Prompts
It’s best to try things yourself. Here are some prompts you can try to test each model. For DeepSeek R1, try this.
The Bottom Line
Magistral (Small/Medium) excels at multi-step reasoning with auditability and is available as an open model and via a fast API. Devstral (Small/Medium) is optimized for developer workflows, especially for agile coding tasks, and can be deployed locally or through Mistral’s API. DeepSeek-R1 (and its distills) focuses on reasoning and code benchmarks, offering high capability but requiring more engineering, and is fully open-source under MIT.
If coding is what you’re looking for, look no further than DeepSeek R1. But nothing wrong in trying Mistral’s models, so give them a shot too. Regarding coding, if you’re looking for a platform where you don’t have to stick to one model, consider Bind AI, which offers you access to Claude 4, Gemini 2.5 Pro, OpenAI o3, DeepSeek R1, and more + a full, cloud IDE for your coding workflows. Try Bind AI now!