
OpenAI recently introduced GPT-5-Codex, a variant of GPT-5 optimized for agentic coding tasks within the OpenAI Codex ecosystem. Not to get confused with the GPT-5 Deep Thinking variant (the best place to try it is here), there’s a distinction. Regardless, the GPT-5 Codex will likely remain one of the benchmarks for advanced AI coding, given that it makes sense to compare it with Anthropic’s Claude Code and Cursor, to determine the ultimate AI coding assistant.
But before we get into the comparison, here are some of the key new features, strengths, and implications the GPT-5 Codex brings to the table:

How GPT-5 Codex enhances your AI coding experience
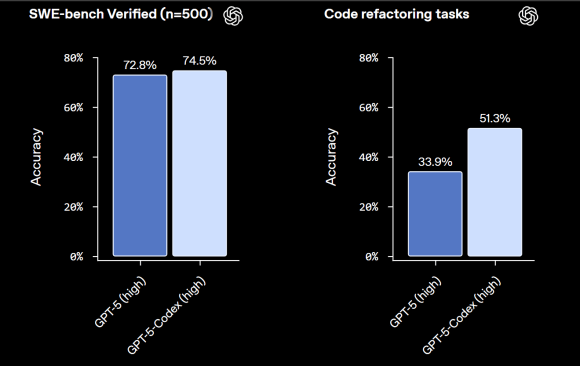
- Greater autonomy: Codex can not just generate snippets, but do more of the “lift” — auto-run tests, refactor, review, propose fixes, etc. This shifts the mental load from “telling AI what to generate” to “supervising / refining” AI’s output.
- Higher reliability: Fewer spurious recommendations and more correct code in reviews mean developers spend less time correcting the AI and more time building features.
- Better handling of real-world codebases: Because of improvements in dependency reasoning, context tracking across files, and visual inputs, more realistic, messy projects are handled better.
- Slower or more resource-intensive for big tasks: The dynamic thinking time implies complex tasks might incur more latency or compute cost. For example, refactoring large projects or deeply intertwined architectural reviews might take more time.
GPT-5 Codex vs Claude Code vs Cursor – coding comparison
To compare, let’s look at what Claude Code (from Anthropic) and Cursor (by Anysphere) are offering; their capabilities, trade-offs, and what kinds of tasks or workflows they are suited for.
Claude Code

Claude Code is an “agentic” coding assistant that lets you work with your codebase via terminal or CLI, integrates with existing developer tools, and can take higher-level commands to manipulate code, run commands, commit, etc.
Here’s how to install Claude Code:
Claude Code Key Features
- Full codebase understanding: Given a directory, Claude Code maps dependencies, understands project structure, can explain architecture, etc., without you having to feed large contexts manually.
- Editing / commits / automation: It can edit files directly, run commands (npm etc.), run tests, lint, and even create pull requests / commits.
- Agentic mode & automation: It has an “auto mode” or “agent mode” where you tell it what to implement/feature to add, and it does more continuous work with minimal repeated prompting.
- Context gathering / environment tuning: It draws in context automatically (reading docs, dependencies, design docs etc.), which helps reduce human overhead in setting up prompts.
Claude Code Trade-Offs / Limitations
- Token / context cost: Automatically pulling in context costs time and tokens. For large codebases or frequent changes, this can become a bottleneck.
- Security / permissions: For some operations (e.g. running certain bash commands, installing packages), explicit permission. Also, risk of unintended changes if automation misfires.
- Dependency on stable project structure: If codebase is messy, poorly documented or structured, agentic tools may struggle more (just as any tool would).
- Cost & availability: Depending on subscription / access level; enterprise / pro plans may be required for high-capability usage.
Cursor
Cursor is an AI-powered code editor / IDE with deep integration of AI tools, native editing, codebase-aware context, “edit by natural language” commands, etc. Rather than being purely about agentic CLI work, it’s more about making daily editing, refactoring, querying the codebase, etc., as frictionless as possible.
Cursor Key Features
- Codebase-aware context: Cursor indexes your whole codebase so you can ask questions like “Where is this API client defined?”, “What logic handles authentication?” etc. No need to paste hundreds of files manually.
- Natural language / inline edits & refactoring: Select parts of code (or even whole classes/functions), describe changes in plain English, and have Cursor apply them in place. Multiple line edits, refactors, etc.
- Error detection & fixing in-context: Cursor catches stack traces, recognizes errors in terminal output, suggests fixes; can help with debugging loops.
- Integration / UI and familiar workflow: It builds on the “look and feel” of a “normal code editor,” merges AI features into editor rather than separate chat windows; supports common extensions, user settings, keybindings.
- Privacy / security options: For example “Privacy Mode” so code is not stored remotely without consent. SOC-2 compliance.
Cursor Trade-Offs / Limitations
- Less automation of agentic tasks: While Cursor can help with edits, committing changes, and suggestions, it doesn’t (or didn’t as of latest documentation) natively handle some of the more “agentic” job-scope that Claude Code or GPT-5-Codex do (like automatically running tests / commits / CLI agents) to as autonomous a degree.
- Dependency on prompt / selection context: For substantial architectural changes, need to guide the AI well; may still require manual structuring of instructions.
- Lag / performance on large codebases: Indexing, context, model latency can become visible for very large repos. Also, depending on model under the hood (e.g. which variant of LLM, subscription, etc.), results vary.
- Cost / licensing / model choice: As with all premium AI tools, heavier usage, enterprise features, or faster models may cost more.
Direct Comparison: GPT-5-Codex vs Claude Code vs Cursor
Below is a comparison across multiple dimensions. Which tool is “best” depends heavily on what you need: speed vs autonomy vs control, small-scale vs large scale, safety / reliability vs creative generation, etc.
| Dimension | GPT-5-Codex | Claude Code | Cursor |
|---|---|---|---|
| Agentic Capability / Autonomy | Very high. Designed to run tests, review code, refactor, and operate as a more “teammate” rather than purely reactive. Best for tasks needing deep reasoning over multi-file projects. | Also high. Claude Code supports editing, running commands, making commits, frequent automation. Good for end-to-end workflows. | Moderate to high. Focused more on editing, selection-based refactoring, context-aware suggestions. Less autonomous in terms of “run all tests, auto commit, CLI agent” though it’s improving. |
| Context Understanding & Large Codebases | Strong. Trained to handle dependencies and visual/screenshot inputs. Better at reasoning over large, messy setups. | Strong. Claude Code maps entire codebase, figures out project structure automatically. | Strong, but becomes more costly (latency / resources) as repo size increases. Works best when user gives sufficiently guided context. |
| Speed & Latency | Variable. For simple tasks very fast; for complex tasks, more thinking time — sometimes considerably more. | Probably similar: automation/time needed to pull in context, test, etc., will slow heavy workflows. | Usually snappier in daily editing & refactoring tasks; likely less latency for small-scale operations. |
| Correctness, Quality of Code / Reviews | Very good. Fewer incorrect/unimportant code review comments; better refactoring scores. (OpenAI) | Good. Because files / structure / dependencies are understood, changes are less likely to break things; but risk remains due to automation. | Good for incremental edits; risk still that large-scale changes or design-level architectural refactors may be shallow unless well guided. |
| Tooling / Integration | Deep integration with Codex CLI, IDE extensions, cloud envs, GitHub, etc. Supports images/screenshots. | Strong integration with developer tools. Works from terminal / CLI; supports design docs, tickets, custom tooling. | Deep integration with editor features: keybindings, UI, extensions. More “hands-in-code” experience vs “agent pushing code”. |
| Control & Safety | High. Tests, review, fewer wrong comments. But deeper automation implies more risk if misused. Also, explicit instructions / oversight still needed. | Similar trade-off: powerful automation means more surface for mistakes. Permissions, prompts are involved for risky operations. | More conservative by nature; user remains more in control of edits. Safer for incremental work. |
| Learning Curve & Setup Cost | Probably steeper: learning when to trust, when to override; setting up tests, dependencies, visual feedback. Also cost/subscription/version requirements. | Moderate: but depending on project complexity, context outputs etc. | Lower: more familiar for developers used to code editors; quicker to adopt in daily coding. |
| Behavior on Edge Cases / Complex Projects | Likely better at handling them due to improved reasoning, dependencies, visual context; but potential for surprises if inputs are ambiguous. | Also good, but may struggle more in very unconventional architectures or when project lacks good structure. | Might struggle to maintain correctness or coherency for large refactors, or where many interdependencies exist unless carefully managed. |
Which Is Best for What Use Case
Given the above, here are some recommendations: which tool is likely “best” depending on developer type, project, and priorities.

Challenges & What to Watch Out For
No tool is perfect. Here are potential pitfalls common to all, but some more acute depending on the tool:
- Over-automation risk: When AI runs tests, commits, edits multiple files automatically, there’s risk of unintended side-effects, dependency breakage, etc.
- Context drift / stale dependencies: If project changes outside AI’s view (e.g. external services, environment, undocumented dependencies), AI suggestions may be incorrect.
- Cost & compute usage: Deep reasoning, tests, refactoring, large contexts cost more in tokens / compute / subscription.
- Security & privacy: Code may contain secrets, proprietary IP; need tools that respect privacy (Cursor’s privacy mode, etc.). Also, dependencies and external commands might be risky.
- Human oversight needed: For production-level code, manually review AI suggestions; especially edge cases, performance, and security.
- Model biases / hallucinations: Even advanced models will hallucinate or make subtle errors; examine carefully.
Bind AI’s Buying Guide
If your priority is deep, autonomous support for a large, complex codebase (tests, refactoring, reviews), then GPT-5-Codex currently seems to be the most advanced; its improvements in code review, visual inputs, and dependency reasoning give it an edge.
If you want a strong middle ground: automation plus control, working from CLI, integrating existing tools, with the ability to issue higher-level directives, Claude Code is extremely compelling.
If your priority is speed, fluid editing, lightweight refactoring, and staying within a familiar editor with minimal setup, Cursor remains a top choice.
In many real-world workflows, a hybrid may work best — e.g., using Cursor or Claude Code for day-to-day edits, and bringing in GPT-5-Codex for architecture shifts, big refactors, or deep reviews.
The Bottom Line
GPT-5-Codex, Claude Code, and Cursor each bring strong, somewhat overlapping but distinct capabilities to the table. If we had to pick one overall “best” given the current state and assuming access, we’d lean GPT-5-Codex for its advanced reasoning, correctness, and autonomy. But for many developers and teams, Claude Code or Cursor might deliver more value per time / money depending on the workflow.
For those of you who prefer working directly in the IDE, Bind AI provides the most seamless option, uniting GPT-5, Claude 4, Gemini 2.5 Pro, DeepSeek R1, and others, and GitHub navigation in a single, integrated workflow. Try Bind AI here.